
In a previous post, I wrote about how I built a competitor monitoring system for a marketing team. We used Firecrawl to detect changes on competitor sites and blog content, and alert the marketing team with a custom report. That was the first phase of a larger project.
The second phase was tracking the competitors’ ads and adding it to our report. The good folks at LinkedIn and Meta publish all the ads running on their platforms in a public directory. You simply enter the company name and it shows you all the ads they run. That’s the easy part.
The tough part is automating visiting the ad libraries on a regular basis and looking for changes. Or, well, it would have been tough if I weren’t using Browserbase.
In this tutorial, I’ll show you how I built this system, highlighting the features of Browserbase that saved me a lot of time. Whether you’re building a competitor monitoring agent, a web research tool, or any AI agent that needs to interact with real websites, the patterns and techniques here will apply.
WHy Browserbase?
Think of Browserbase as AWS Lambda, but for browsers. Instead of managing your own browser infrastructure with all the pain that entails, you get an API that spins up browser instances on demand, with features you need to build reliable web agents.
Want to persist authentication across multiple scraping sessions? There’s a Contexts API for that. Need to debug why your scraper failed? Every session is automatically recorded and you can replay it like a DVR. Running into bot detection? Built-in stealth mode and residential proxies make your automation look human.
For this project, I’m using Browserbase to handle all the browser orchestration while I focus on the actual intelligence layer: what to monitor, how to analyze it, and what insights to extract. This separation of concerns is what makes the system maintainable.
What We’re Building: Architecture Overview
This agent monitors competitor activity across multiple dimensions and generates actionable intelligence automatically.
The system has five core components working together. First, there’s the browser orchestration layer using Browserbase, which handles session management, authentication, and stealth capabilities. This is the foundation that lets us reliably access ad platforms.
Second, we have platform-specific scrapers for LinkedIn ads, Facebook ads, and landing pages. Each scraper knows how to navigate its platform, handle pagination, and extract structured data.
Third, there’s a change detection system that tracks what we’ve seen before and identifies what’s new or different.
Fourth, we have an analysis engine that processes the raw data to identify patterns, analyze creative themes, and detect visual changes using perceptual hashing.
Finally, there’s an intelligence reporter that synthesizes everything and generates strategic insights using GPT-4.
Each component is independent and can be improved or replaced without affecting the others. Want to add a new platform? Write a new scraper module. Want better AI insights? Swap out the analysis prompts. Want to store data differently? Replace the storage layer.
Setting Up Your Environment
First, you’ll need accounts for a few services. Sign up for Browserbase at browserbase.com and grab your API key and project ID from the dashboard. The free tier gives you enough sessions to build and test this system. If you want the AI insights feature, you’ll also need an OpenAI API key.
Create a new project directory, set up a Python virtual environment, and install the key dependencies:
# Create and activate virtual environment
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install dependencies
pip install browserbase playwright pillow imagehash openai python-dotenv requests
playwright install chromiumCreate a .env file to store the keys you got from Browserbase.
# .env file
BROWSERBASE_API_KEY=your-api-key-here
BROWSERBASE_PROJECT_ID=your-project-id-here
OPENAI_API_KEY=sk-your-key-hereBuilding the Browser Manager: Your Gateway to Browserbase
The browser manager is the foundation of everything. This class encapsulates all the Browserbase interaction and provides a clean interface for the rest of the system. It handles session lifecycle, connection management, and proper cleanup.
class BrowserManager:
def __init__(self, api_key: str, project_id: str, context_id: Optional[str] = None):
self.api_key = api_key
self.project_id = project_id
self.context_id = context_id
# Initialize the Browserbase SDK client
# This handles all API communication with Browserbase
self.bb = Browserbase(api_key=api_key)
# These will hold our active resources
# We track them as instance variables so we can clean up properly
self.session = None
self.playwright = None
self.browser = None
self.context = None
self.page = None
def connect_browser(self):
"""
Connect to the Browserbase session using Playwright.
This is where the magic happens - we're connecting to a real Chrome
browser running in Browserbase's infrastructure. From here on, it's
just standard Playwright code, but with all of Browserbase's superpowers.
"""
if not self.session:
raise RuntimeError("No session created. Call create_session() first.")
# Initialize Playwright
self.playwright = sync_playwright().start()
# Connect to the remote browser using the session's connect URL
# This is CDP (Chrome DevTools Protocol) under the hood
self.browser = self.playwright.chromium.connect_over_cdp(
self.session.connectUrl
)
# Get the default context and page that Browserbase created
# Note: If you specified a context_id, this context will have your
# saved authentication state automatically loaded
self.context = self.browser.contexts[0]
self.page = self.context.pages[0]
return self.pageLet’s write a function to create a new Browserbase session with custom configuration.
We’ll enable stealth to make our agent look like a real human and not trip up the bot detectors. And we’ll set up a US proxy.
You can also set session timeouts, or keep sessions alive even if your code crashes (though we aren’t doing that here).
def create_session(self,
timeout: int = 300,
enable_stealth: bool = True,
enable_proxy: bool = True,
proxy_country: str = "us",
keep_alive: bool = False) -> Dict[str, Any]:
session_config = {
"projectId": self.project_id,
"browserSettings": {
"stealth": enable_stealth,
"proxy": {
"enabled": enable_proxy,
"country": proxy_country
} if enable_proxy else None
},
"timeout": timeout,
"keepAlive": keep_alive
}
# If we have a context ID, include it to reuse authentication state
# This is the secret sauce for avoiding repeated logins
if self.context_id:
session_config["contextId"] = self.context_id
self.session = self.bb.sessions.create(**session_config)
session_id = self.session.id
connect_url = self.session.connectUrl
replay_url = f"https://www.browserbase.com/sessions/{session_id}"
return {
"session_id": session_id,
"connect_url": connect_url,
"replay_url": replay_url
}You’ll notice we get back a replay URL. This is where we can actually watch the browser sessions and debug what went wrong.
Next, we connect to our browser session using Playwright, an open-source browser automation library by Microsoft.
def connect_browser(self):
self.playwright = sync_playwright().start()
self.browser = self.playwright.chromium.connect_over_cdp(
self.session.connectUrl
)
# Get the default context and page that Browserbase created
self.context = self.browser.contexts[0]
self.page = self.context.pages[0]
return self.pageFinally, we want to clean up all resources and close our browser sessions:
if self.page:
self.page.close()
if self.context:
self.context.close()
if self.browser:
self.browser.close()
if self.playwright:
self.playwright.stop()So basically you create a session with specific settings, then connect to it, do some work, disconnect, and connect again later.
The configuration parameters I exposed are the ones I found most useful in production. Stealth mode is almost always on because modern platforms are too good at detecting automation. Proxy support is optional but recommended for platforms that rate-limit by IP.
Creating and Managing Browserbase Contexts
Before we build the scrapers, I want to show you one of Browserbase’s most powerful features: Contexts.
A Context in Browserbase is like a reusable browser profile. It stores cookies, localStorage, session storage, and other browser state.
You can create a context once with all your authentication, then reuse it across multiple browser sessions. This means you log into LinkedIn once, save that authenticated state to a context, and every future session can reuse those credentials without going through the login flow again.
We don’t actually need this feature for scraping LinkedIn Ads Library because it’s public, but if you want to scrape another ad library that requires a login, it’s very useful. Here’s a sample function that handles the one-time authentication flow for a platform and saves the resulting authenticated state to a reusable context.
def create_authenticated_context(api_key: str, project_id: str,
platform: str, credentials: Dict[str, str]) -> str:
# Create a new context
bb = Browserbase(api_key=api_key)
context = bb.contexts.create(projectId=project_id)
context_id = context.id
# Create a session using this context
# Any cookies or state we save will be persisted to the context
with BrowserManager(api_key, project_id, context_id=context_id) as mgr:
session_info = mgr.create_session(timeout=300)
page = mgr.connect_browser()
if platform == "linkedin":
page.goto("https://www.linkedin.com/login", wait_until="networkidle")
page.fill('input[name="session_key"]', credentials['email'])
page.fill('input[name="session_password"]', credentials['password'])
page.click('button[type="submit"]')
page.wait_for_url("https://www.linkedin.com/feed/", timeout=30000)
elif platform == "facebook":
# Similar flow for Facebook
return context_idAuthentication state is saved to the context ID which you can then reuse to avoid future logins.
Building Platform-Specific Scrapers
Now we get to the interesting part: actually scraping data from ad platforms. I’m only going to show you the LinkedIn ad scraper because it demonstrates several important patterns and the concepts are the same across all platforms.
It’s really just one function that takes a Browserbase page object and returns structured data. This separation means the browser management is completely isolated from the scraping logic, which makes everything more testable and maintainable.
First we navigate to the ad library and wait until the network is idle as it loads data dynamically. We then fill the company name into the search box, add a small delay to mimic human behaviour, then press enter.
def scrape_linkedin_ads(page: Page, company_name: str, max_ads: int = 20) -> List[Dict[str, Any]]:
ad_library_url = "https://www.linkedin.com/ad-library"
page.goto(ad_library_url, wait_until="networkidle")
search_box = page.locator('input[aria-label*="Search"]')
search_box.fill(company_name)
time.sleep(1) # Human-like pause
search_box.press("Enter")
# Wait for results to load
# LinkedIn's ad library is a SPA that loads content dynamically
time.sleep(3)
ads_data = []
scroll_attempts = 0
max_scroll_attempts = 10The LinkedIn ads library is a SPA that loads content dynamically so we wait for it to load before we start our scraping.
We’re going to implement infinite scroll to load more ads. First we find ad cards currently visible, and use multiple selectors in case LinkedIn changes their markup.
while len(ads_data) < max_ads and scroll_attempts < max_scroll_attempts:
ad_cards = page.locator('[data-test-id*="ad-card"], .ad-library-card, [class*="AdCard"]').all()
for card in ad_cards:
if len(ads_data) >= max_ads:
break
try:
ad_data = {
"platform": "linkedin",
"company": company_name,
"scraped_at": time.strftime("%Y-%m-%d %H:%M:%S")
}
try:
headline = card.locator('h3, [class*="headline"], [data-test-id*="title"]').first
ad_data["headline"] = headline.inner_text(timeout=2000)
except:
ad_data["headline"] = None
# Extract body text/description
try:
body = card.locator('[class*="description"], [class*="body"], p').first
ad_data["body"] = body.inner_text(timeout=2000)
except:
ad_data["body"] = None
# Extract CTA button text if present
try:
cta = card.locator('button, a[class*="cta"], [class*="button"]').first
ad_data["cta_text"] = cta.inner_text(timeout=2000)
except:
ad_data["cta_text"] = None
# Extract image URL if available
try:
img = card.locator('img').first
# Scroll image into view to trigger lazy loading
img.scroll_into_view_if_needed()
time.sleep(0.5) # Give it time to load
ad_data["image_url"] = img.get_attribute('src')
except:
ad_data["image_url"] = None
# Extract landing page URL
try:
link = card.locator('a[href*="http"]').first
ad_data["landing_url"] = link.get_attribute('href')
except:
ad_data["landing_url"] = None
# Extract any visible metadata (dates, impressions, etc)
try:
metadata = card.locator('[class*="metadata"], [class*="stats"]').all_inner_texts()
ad_data["metadata"] = metadata
except:
ad_data["metadata"] = []
# Only add the ad if we extracted meaningful data
if ad_data.get("headline") or ad_data.get("body"):
ads_data.append(ad_data)
except Exception as e:
print(f"Error extracting ad card: {e}")
continue
# Scroll to load more ads
page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(2) # Wait for new content to load
scroll_attempts += 1
return ads_dataI’m limiting scroll attempts to prevent infinite loops on platforms that don’t load additional content.
I’m also adding small delays that mimic human behavior. The time dot sleep calls between actions aren’t strictly necessary for functionality, but they make the automation look more natural to bot detection systems. Real humans don’t type instantly and don’t scroll at superhuman speeds.
You can repeat these patterns yourself to scrape other ad libraries, landing pages and so on.
Building the Change Tracking Database
Now we need persistence to track what we’ve seen before and identify what’s new. We’ll create a SQLite database with two main tables: one for ad snapshots, and one for tracking detected changes. Each table has the fields we need for analysis, plus a snapshot date so we can track things over time.
I’m not going to share the code here because it’s just a bunch of SQL commands to set up the tables, like this:
CREATE TABLE IF NOT EXISTS ads (
id INTEGER PRIMARY KEY AUTOINCREMENT,
competitor_id TEXT NOT NULL,
platform TEXT NOT NULL,
ad_identifier TEXT,
headline TEXT,
body TEXT,
cta_text TEXT,
image_url TEXT,
landing_url TEXT,
metadata TEXT,
snapshot_date DATETIME NOT NULL,
UNIQUE(competitor_id, platform, ad_identifier, snapshot_date)
)For every ad we scrape, we simply store it in the table. We also give each ad a unique identifier. Normally I would suggest hashing the data so that any change in a word or pixel gives us a new identifier. But a basic implementation can be something like
ad_identifier = f"{ad.get('headline', '')}:{ad.get('body', '')}"[:200]So if the headline or body changes, it is a new ad. We can then do something like:
for ad in current_ads:
ad_identifier = f"{ad.get('headline', '')}:{ad.get('body', '')}"[:200]
cursor.execute("""
SELECT COUNT(*) FROM ads
WHERE competitor_id = ? AND platform = ? AND ad_identifier = ?
""", (competitor_id, platform, ad_identifier))
count = cursor.fetchone()[0]
if count == 0:
new_ads.append(ad)
if new_ads:
self._log_change(
competitor_id=competitor_id,
change_type="new_ads",
platform=platform,
change_description=f"Detected {len(new_ads)} new ads on {platform}",
severity="high" if len(new_ads) > 5 else "medium",
data={"ad_count": len(new_ads), "headlines": [ad.get('headline') for ad in new_ads[:5]]}
)
return new_adsThe log change function stores it in our changes table, which we then use to generate a report.
Generating AI-Powered Intelligence Reports
Now we take all this raw data and turning it into actionable insights using AI. Most of this is just prompt engineering. We pass in all the data we collected and the changes we’ve detected and ask GPT-5 to analyze it and generate a report:
prompt = f"""Generate an executive summary of competitive intelligence findings.
High Priority Changes ({len(high_severity)}):
{json.dumps([{k: v for k, v in c.items() if k in ['competitor_id', 'change_type', 'change_description']} for c in high_severity[:10]], indent=2)}
Medium Priority Changes ({len(medium_severity)}):
{json.dumps([{k: v for k, v in c.items() if k in ['competitor_id', 'change_type', 'change_description']} for c in medium_severity[:10]], indent=2)}
Please provide:
1. **TL;DR**: A two to three sentence summary of the most important findings
2. **Key Threats**: Competitive moves we should be concerned about and why
3. **Opportunities**: Gaps or weaknesses we could exploit to gain advantage
4. **Recommended Actions**: Top three strategic priorities based on this intelligence
Keep it concise and focused on actionable insights. Format in markdown."""Running Our System
And that’s our competitive analysis system! You can write a main.py file that coordinates all the components we’ve built into a cohesive workflow.
I’ve only shown you how to scrape the LinkedIn ads library but you can use similar code to do it for other platforms.
If anything goes wrong, the Session Replays are your friends. This is where you can see our system navigate different pages, and what the DOM looks like.
So, for example, if you’re trying to click on an element and there’s an error, you can check the session replay and see that the element didn’t load. Then you try to add a delay to let it load, and run it again.
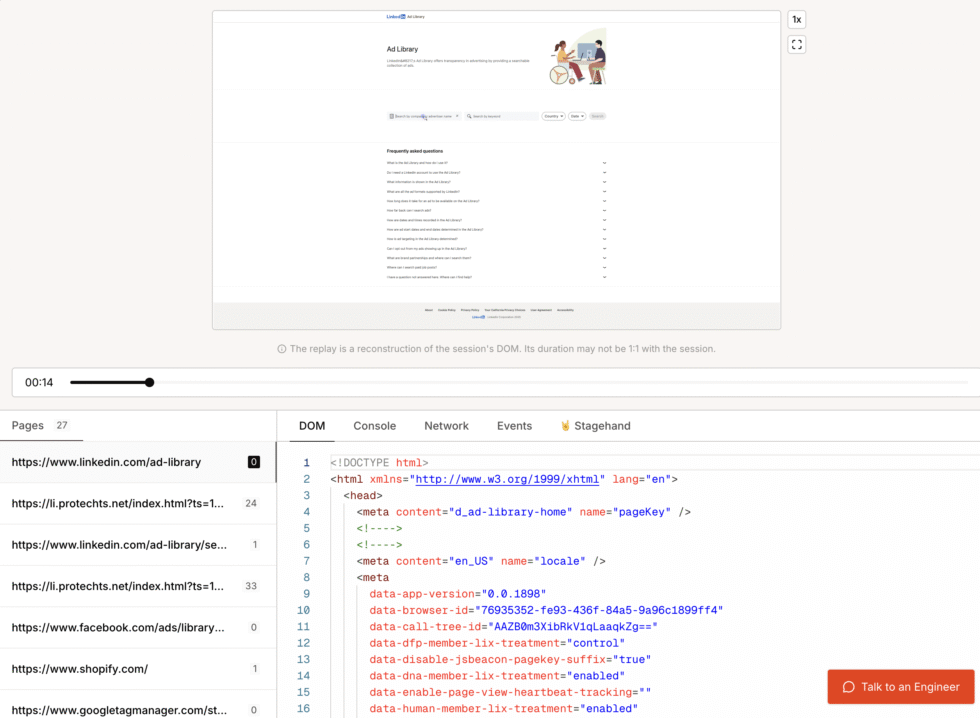
Browserbase also has a playground where you can iterate rapidly and run browser sessions before you figure out what works.
Next Steps
As I mentioned, this is part of a larger project for my client. There are so many directions you could take this.
You could add more platforms like Twitter ads, or Google Display Network, each platform is just another scraper function using the same browser management infrastructure. You could implement trend analysis that tracks how competitor strategies evolve over months. You could create a dashboard for visualizing the intelligence using something like Streamlit.
More importantly, these same patterns work for any AI agent that needs to interact with the web. With Browserbase, you can build:
- Research assistants that gather information from multiple sources and synthesize it into reports.
- Data collection agents that extract structured data from websites at scale for analysis.
- Workflow automation that bridges systems without APIs by mimicking human browser interactions.
If you need help, reach out to me!